
A more accurate perspective emerges when you recognize that “large language models” (LLMs) extend beyond just ChatGPT. Such a platform has gained tremendous popularity due to its accessibility – any user can use a pre-trained system through a simple OpenAI structure – more so than the mechanism behind it. In reality, building and fine tuning large language models has been an ongoing process for quite a while.
LLMs have had a giant effect on artificial intelligence (AI). Such systems allow computers to perform objectives that, for many years, were considered the preserve of live agents. LLM programs are actively utilized in various fields, from chatbots and digital helpers to online translators and content formation. Let’s discuss what LLMs are and how to build a large language model or set it up.
The Definition of LLM
A large language model (LLM) is a kind of AI that may form and comprehend text. Such structures are studied on large databases of phrases and codes. They may be utilized to perform various tasks, including translation, original content generation, and informative responses to multiple inquiries.
You can create an LLM from scratch, tailored to the personal aims of your firm, or utilize fine-tuning. The second option involves retraining a pre-teached LLM based on a novel database. It allows you to perfect the productivity of the LLM on particular objectives or adapt it to certain conditions.
Critical Advantages of Building or Fine-Tuning LLM
Creating from scratch or fine-tuning an LLM provides significant opportunities for enterprises. According to McKinsey, generative AI could generate $2.6 trillion to $4.4 trillion annually across 63 use cases, with a major impact across all fields. LLM is a valuable solution for businesses that generate giant amounts of data. Let’s consider the LLM meaning in the competitive conditions:
- The expanded function of natural language processing (NLP): LLMs such as GPT-3.5 broaden the capabilities of NLP by allowing AI-backed structures to process and interpret queries and spoken language like live agents do. Unlike the previous approach, which involved utilizing ML-ruled systems to comprehend data, LLMs simplify and perfect this procedure.
- Language translation: most LLM systems can be utilized to translate sentences from one language to another. The structure relies on deep learning mechanisms, e.g., recurrent neural networks, to determine features of dissimilar dialects. It simplifies communication between representatives of multiple cultures and overcomes language barriers.
LLMs easily comprehend human phrases, making them optimal for performing routine or time-consuming jobs. So, economic experts may use such platforms to digitize money transactions and process insights, eliminating manual data entry. LLMs’ ability to increase efficiency by automating objectives is one of the reasons why they have become indispensable in many firms.
Key Considerations When Starting or Fine Tuning LLM
The process of creating and fine-tuning LLM differs depending on the category of LLM you plan to achieve, whether it is to optimize text or dialogue. The system’s effectiveness mainly depends on the database and the model architecture. Let’s consider the main points of LLM formation.
Technical control
Naturally, constructing and setting up an LLM requires significant technical knowledge. A machine learning expert will undoubtedly be able to fine-tune the LLM. However, you must hire a department of LLM machine learning specialists to create an LLM from scratch.
Volumes of information, quality, and ethical component
When building your LLM, you need a lot of information. LLaMA relies on the teaching database, which consists of 1.4 trillion tokens; their entire weight is 4.6 terabytes. ChatGPT was created using 1.5 trillion tokens.
Fine tuning large language models demands using less data. Let’s look at the instance of Med-PaLM 2 from Google, which was finalized with PaLM LLM. According to the report, the AI team utilized fine-tuning and handled approximately 193,000 templates, equivalent to 19 and 39 million tokens.

Tracking the volume and quality of insights is essential since inaccurate data will lead to mistakes in the LLM work.
System performance
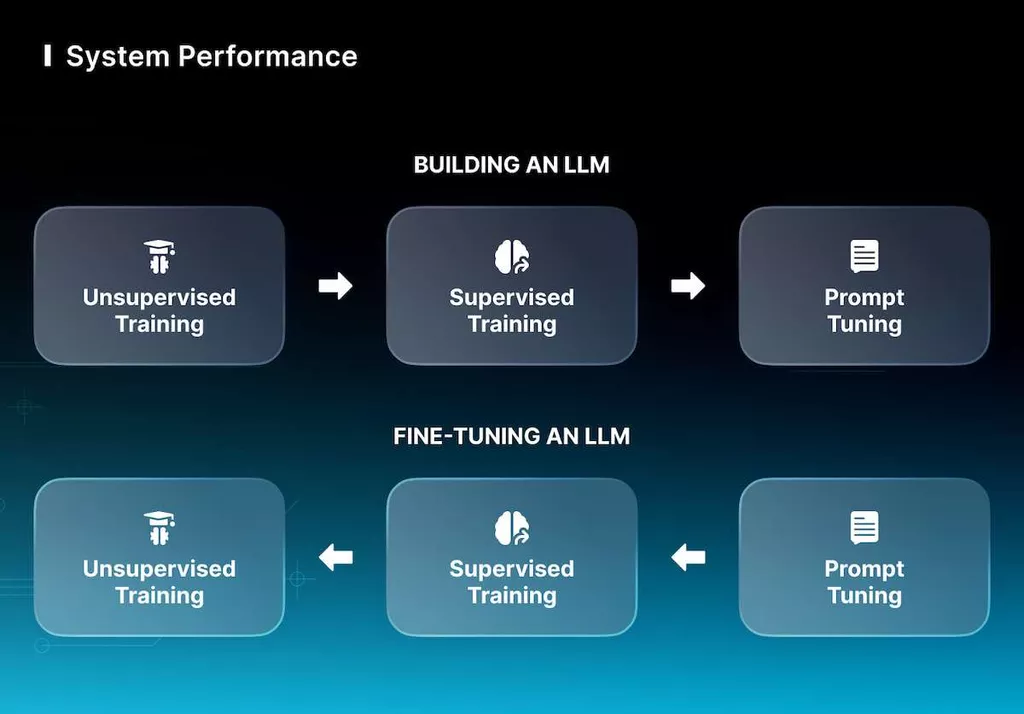
Fine-tuning the LLM may be sufficient, depending on the enterprise’s goals. There are multiple options for adapting LLM to your company’s needs and raising efficiency, but we advise you to choose the opposite method. Let’s analyze its essence.
In most situations, training a basic model from scratch begins with unsupervised training. Then, the supervised training phase is utilized to fine-tune the LLM, and the final step is prompting and prompt tuning to obtain the demanded result.
We recommend beginning with prompt tuning for fine-tuning since it is the most minor resource-intensive procedure. If the system does not function properly, we move on to supervised training. Have all these instruments failed? Then, we launch unsupervised training and collect a suitable database to organize preliminary training of the structure.
Maintenance and update
Whether you’ve built your LLM from scratch or have fine-tuned it, LLM demands reiteration to stay effective with up-to-date data. Reiteration involves changing the model, considering novel information, or adjusting aims.
Firms that have launched successful LLM projects like OpenAI constantly present updated versions of GPT-3. Although ChatGPT teaching ended in the fall of 2021, OpenAI utilizes up-to-date user behavior facts to perfect the framework’s predictive activity.
When Should You Consider Building or Fine Tuning LLM?
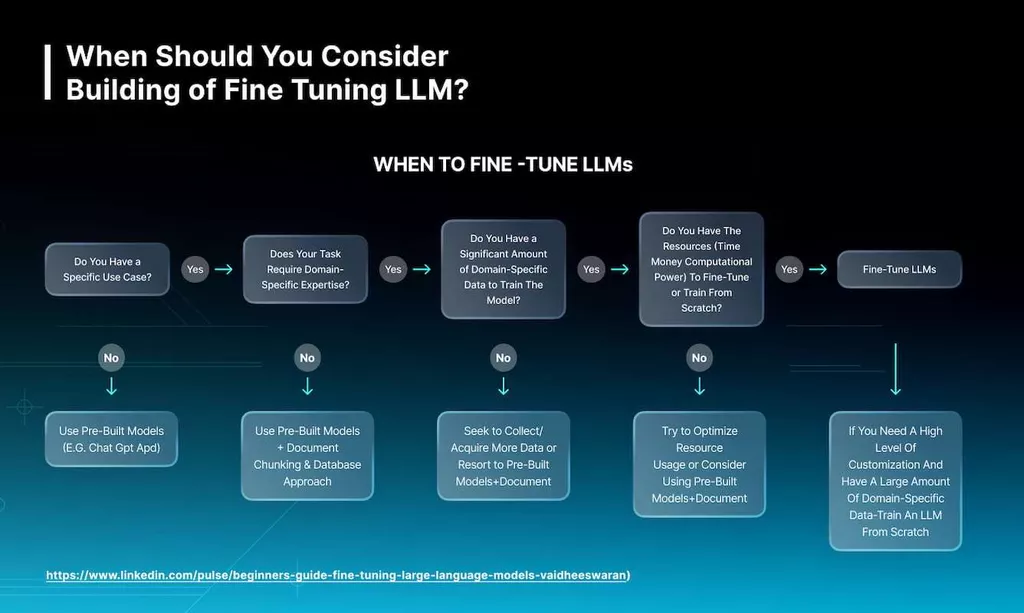
The question often arises: is it worth creating an LLM from scratch, or does it need to perfect the current platform with an individual database? Let’s consider which options to choose in different situations.
Building a system from scratch is necessary if you are planning a non-standard use case not satisfied by popular LLMs or if the platform will become the primary driver of your business. Besides, suppose you store a massive volume of confidential insights. In that case, it makes sense to form your LLM to use it to your advantage without worrying about the security of the information.
When we discuss fine tuning large language models, you have several options: choose existing open-source LLMs or add a commercial LLM API. A commercial LLM is an optimal solution for teams with limited technical knowledge, while an open-source structure provides the maximum control. It is vital to remember that some of the threats that arise during the fine-tuning process are related to biases and threats to information security.

Costs of Building and Fine Tuning LLM
Having realized all the profits of owning an LLM, let’s determine the value of creating different options. The prices of building from scratch or fine-tuning highly depend on the volume of the structure and its efficiency parameters. Let’s look at variants of pricing of multiple categories of platforms.
Model construction costs
When you consider how to train a large language model from scratch, it is necessary to define its structure, paying attention to the platform’s volume. Scale solutions, e.g., GPT-4, are implemented to solve many issues; they have significant knowledge in different areas. It is possible to significantly decrease the size of the structure when performing highly specialized work.
Let’s consider the Falcon 7B system; it is a medium-sized LLM with average features.
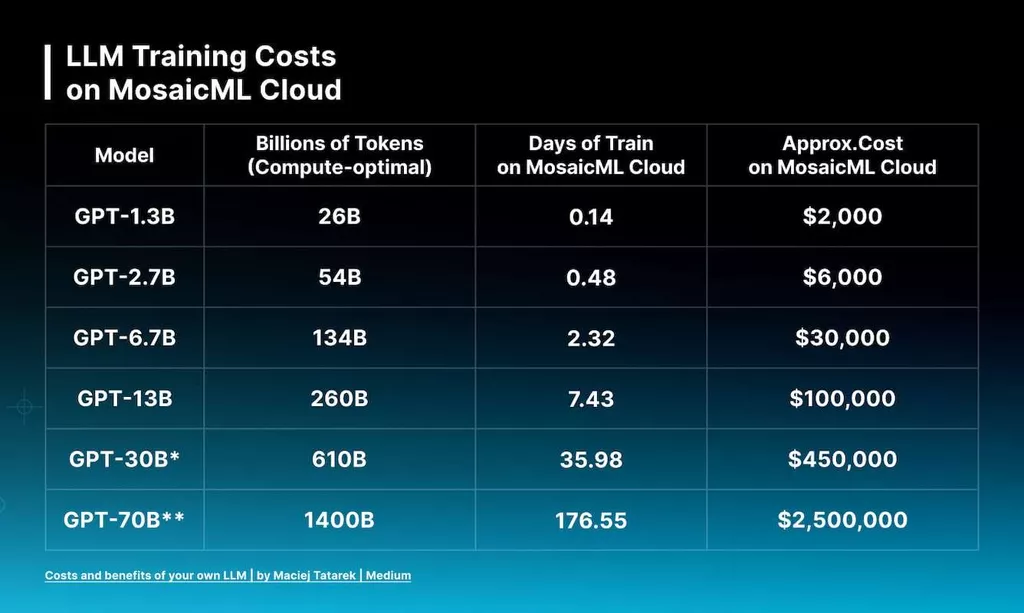
MosaicML, now under the ownership of Databricks for a significant $1.3 billion, provides a user-friendly framework for training and deploying Large Language Models (LLMs). Under their pricing policy, creating a GPT-3 equivalent with 30 billion parameters is now remarkably affordable, costing approximately $450,000. For a smaller 7-billion-parameter model, the cost is reduced even further to $30,000, all while maintaining performance levels comparable to more costly alternatives. These figures represent the expenses associated with fine-tuning these models.
Fine-tuning costs
Reaching a novel state-of-the-art (SOTA) on a research database by fine-tuning can be cost-effective. Consider this example: CRFM Stanford applied the Huggingface GPT PubMed insights leveraging the MosaicML Platform to form a 2.7-billion-parameter platform. The cost of such a digital product was $38 thousand.
Fine-tuning larger structures, e.g., a 65-billion-parameter structure, can be expensive due to the high demands on GPUs. However, special techniques like LoRa or QLoRa offer effective options. LoRa shows that changing the model does not require retraining the fundamentals of the system, cutting computational expenditures. QLoRa improves procedures with computational techniques, maintaining performance and increasing efficiency. Utilizing QLoRa instruments to fine-tune your Falcon 7B system can be a cost-effective solution with Google Colab Pro, which costs $9.99 monthly and can be canceled anytime.
How to Estimate Large Language Structures?
As language models become more accessible, getting lost in all the variants is simple. How can we measure the platforms’ activity and compare them to each other? Can we say with certainty that one system is better than another? Let’s consider the primary techniques for assessing building or fine-tuning models:
- Perplexity: it is a popular indicator to research the productivity of language structures. It quantifies how well the system forecasts a text pattern. Less perplexity means better performance.
- Human evaluation: such a procedure involves utilizing appraisers who study the quality of the output of the language system. Such experts estimate the generated answers based on multiple criteria: relevance, fluency, consistency, and quality. Such an approach provides a subjective review of the performance of the structure.
- BLEU (Bilingual Evaluation Understudy) serves as a frequently employed evaluation system in machine translation tasks. It assesses the output against reference translations, examining the degree of similarity between them. The BLEU score varies between 0 and 1, with a higher value signifying superior performance.
Current assessment methods are not ideal as they often do not capture the diversity and creativity of LLM output. The fact is that metrics concentrate only on precision and relevance, losing sight of the importance of getting creative and new answers.
The Fundamental Difficulties with LLM
Now that we have explained how to build an LLM, it is necessary to discuss some of the disadvantages of the system. Although LLMs demonstrate outstanding results, it is vital to remember some of their restrictions and possible risks. Realizing these complexities allows us to make informed decisions about the reliable use of LLM, promoting the introduction of ethically compliant platforms:
- Context windows restrict the volume of past information the platform considers when composing novel tokens. Such restrictions prevent the system from capturing long-lasting connections, comprehending wider context, and maintaining coherent text. Important insights outside the window may be missed, leading to imperfect realizing and potentially incorrect answers.
- Accuracy is another restriction of LLMs, e.g., ChatGPT, as they sometimes produce wrong results. Despite significant productivity, LLMs are prone to inaccuracies due to systematic mistakes in the teaching dataset, lack of common sense, and platform dependence on statistical parameters. They may create plausible but fake insights or misinterpret clues.
Training and fine tuning LLM requires significant computing power and involves special equipment. Such resources are associated with substantial expenditures, which makes LLM inaccessible to many enterprises.
Final Thoughts
In the dynamic sphere of AI-ruled instruments and machine learning, the role of LLM is of utmost importance. Their ability to interpret and imitate human language has created significant potential in multiple fields.
MetaDialog trains modern custom significant language platforms based on user input tailored to each client’s goals. Such solutions can create responses for different use cases and generate output in various languages. Imagine getting a custom ChatGPT with maximum performance.
You can test the MetaDialog chatbot for free. Just add a link to your website or upload a document. The system will process this data and receive your intelligent chatbot in a few minutes. Your business must keep up with the times!